
Definizione di matrice di confusione
L’elemento sulla riga i e sulla colonna j è il numero assoluto oppure la percentuale di casi della classe “vera” i che il classificatore ha classificato nella classe j.
Sulla diagonale ci sono i casi classificati correttamente, gli altri sono errori.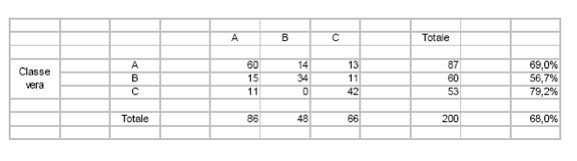
Nel training set ci sono 200 casi.
- Nella classe A ci sono 87 casi:
- 60 sono classificati correttamente come A
- 27 sono classificati erroneamente, dei quali 14 come B e 13 come C
- Sulla classe A l’accuratezza è 60 / 87 = 69,0%. sulla classe B l’accuratezza è il 56,7% e sulla classe C il 79,2%.
- L’accuratezza complessiva è 136 / 200 = 68,0%.
Il valore di questa classificazione dipende non solo dalle percentuali, ma anche dal costo delle singole tipologie di errore.
Se C è la classe che risulta più importante (per valutazioni ad esempio economiche) classificare bene, il risultato che abbiamo ottenuto è positivo (si noti che non si commette mai l’errore di classificare un C come B).
Se si conoscono i costi delle conseguenze di ciascuna tipologia di errore di classificazione, si possono determinare i costi totali di errore (ad esempio, se la classificazione di un cliente di classe A nella classe B costa 3, possiamo costruire una matrice dei costi che nella cella in riga A e colonna B contiene 14 * 3 = 42).
Continua a leggere:
- Successivo: Definizione di lift
- Precedente: Introduzione ai criteri di valutazione di una classificazione
Per approfondire questo argomento, consulta le Tesi:
- Un analisi statistica su come le recensioni possono influenzare la scelta di acquisto dei consumatori
- Sistemi web-based di analisi strategica: Business Intelligence e Big Data
- Il Data mining a supporto dei processi decisionali in azienda
- L'evoluzione dei sistemi informativi e di controllo aziendali
- Analisi dei processi di CRM nel web: electronic customer relationship management
Puoi scaricare gratuitamente questo appunto in versione integrale.
Forse potrebbe interessarti:
Il Data mining a supporto dei processi decisionali in azienda
 Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Login
Oppure utilizza il tuo account
 o
o
