
Esempio applicativo di clusterizzazione non supervisionata
Esemplificazione con sole due variabili.
Si ricorda che la formula per il calcolo della distanza euclidea tra i
punti A di coordinate (x1, y1) e B di coordinate (x2, y2) è: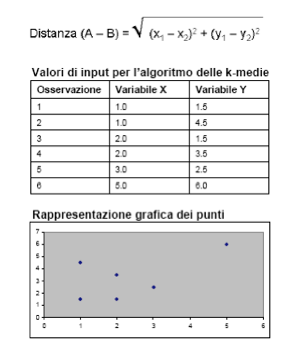
Prima iterazione dell’algoritmo.
- Assumiamo k = 2 (due cluster)
- Scegliamo arbitrariamenti i centri C1(1.0, 1.5), C2(2.0, 1.5) e
calcoliamo le distanze da tali centri di tutte le osservazioni presenti
nella tabella di input, utilizzando la formula della distanza euclidea.
- Otterremo i seguenti risultati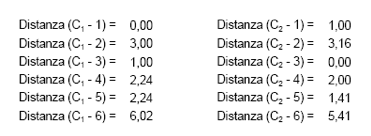
Assegnando ogni osservazione al cluster avente come centro il punto posto a distanza minima, otterremo i due cluster:
- Cluster 1: osservazioni 1, 2
- Cluster 2: osservazioni 3, 4, 5, 6
Adesso ricalcoliamo il centro di ogni cluster:
- Cluster 1:
x = (1.0 + 1.0) / 2 = 1.0
y = (1.5 + 4.5) / 2 = 3.0
- Cluster 2:
x = (2.0 + 2.0 + 3.0 + 5.0) / 4 = 3.0
y = (1.5 + 3.5 + 2.5 + 6.0) / 4 = 3.375
I nuovi centri sono dunque:
- C1(1.0, 3.0)
- C2(3.0, 3.75)
Dal momento che differiscono da quelli iniziali, è necessaria una nuova
iterazione dell’algoritmo, che ci fornisce i seguenti dati:
Assegnando ogni osservazione al cluster avente come centro il punto posto a distanza minima, otterremo i due nuovi cluster:
- Cluster 1: osservazioni 1, 2, 3
- Cluster 2: osservazioni 4, 5, 6
Adesso ricalcoliamo il centro di ogni cluster:
- Cluster 1:
x = (1.0 + 1.0 + 2.0) / 3 = 1.33
y = (1.5 + 4.5 + 1.5) / 3 = 2.50
- Cluster 2:
x = (2.0 + 3.0 + 5.0) / 3 = 3.33
y = (3.5 + 2.5 + 6.0) / 3 = 4.00
I nuovi centri sono:
- C1(1.33, 2.50)
- C2(3.33, 4.00)
Dal momento che differiscono da quelli precedenti, è necessaria una
nuova iterazione e così a seguire fino a quando le coordinate dei nuovi
centri calcolati non siano uguali a quelle dei precedenti (a meno di uno
scarto da definire in fase iniziale).
Una clusterizzazione ottimale per l’algoritmo delle k-medie è quella che
presenta un valore minimo dell’errore quadratico (somma dei quadrati
delle differenze fra le osservazioni e i centri dei cluster di
appartenenza).
Continua a leggere:
- Successivo: Considerazioni generali sul metodo delle k-medie
- Precedente: Clusterizzazione non supervisionata - Introduzione algoritmo della k – medie
Per approfondire questo argomento, consulta le Tesi:
- Un analisi statistica su come le recensioni possono influenzare la scelta di acquisto dei consumatori
- Sistemi web-based di analisi strategica: Business Intelligence e Big Data
- Il Data mining a supporto dei processi decisionali in azienda
- L'evoluzione dei sistemi informativi e di controllo aziendali
- Analisi dei processi di CRM nel web: electronic customer relationship management
Puoi scaricare gratuitamente questo appunto in versione integrale.
Forse potrebbe interessarti:
Sistemi web-based di analisi strategica: Business Intelligence e Big Data
 Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Login
Oppure utilizza il tuo account
 o
o
