
Competenze implicate nel processo di data mining
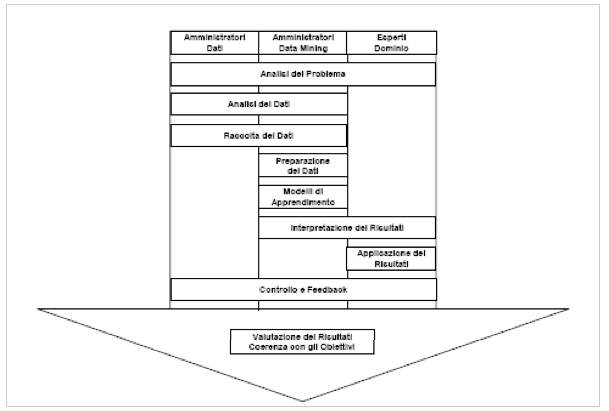
Il processo di data mining implica la collaborazione stretta tra diverse competenze all’interno dell’impresa. Nella parte alta della freccia possiamo vedere le competenze. L’incrocio tra la fascia verticale e la fascia orizzontale individuano il grado di coinvolgimento.
METODOLOGIE DI ANALISI: INTRODUZIONE
Le attività di data mining possono essere classificate in categorie sulla base delle funzionalità e, conseguentemente, degli obiettivi dell’analisi.
La presenza o meno di una variabile target ci consente di distinguere tra processi di data mining in apprendimento supervisionato (es. analisi di loyalty nella telefonia mobile – esiste attributo che identifica classe di appartenenza) e processi di data mining in apprendimento non supervisionato (es. cluster analysis – non esiste attributo, le classi di appartenenza vengono determinate sulla base di ricorrenze, affinità e difformità presenti nel data set).
Procedendo nella classificazione, è possibile identificare sette funzionalità principali di data mining.
- APPRENDIMENTO SUPERVISIONATO:
1.caratterizzazione e discriminazione;
2.classificazione;
3.modelli di stima;
4.modelli di serie storiche.
- APPRENDIMENTO NON SUPERVISIONATO:
5.regole associative;
6.clustering;
7.descrizione e visualizzazione.
Continua a leggere:
- Successivo: Metodologie di analisi: apprendimento supervisionato
- Precedente: Standardizzazione del processo di data mining
Per approfondire questo argomento, consulta le Tesi:
- Un analisi statistica su come le recensioni possono influenzare la scelta di acquisto dei consumatori
- Sistemi web-based di analisi strategica: Business Intelligence e Big Data
- Il Data mining a supporto dei processi decisionali in azienda
- L'evoluzione dei sistemi informativi e di controllo aziendali
- Analisi dei processi di CRM nel web: electronic customer relationship management
Puoi scaricare gratuitamente questo appunto in versione integrale.
Forse potrebbe interessarti:
Sistemi web-based di analisi strategica: Business Intelligence e Big Data
 Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Ricevi informazioni sui nostri servizi, sulle offerte e non perdere news e consigli su università e lavoro.
Login
Oppure utilizza il tuo account
 o
o
